Epidemiologia e Statistica
| Riportiamo i termini più usati in epidemiologia e statistica. Alcune voci sono più comuni nella espressione in lingua inglese; pertanto per ciascuna di esse sarà possibile linkarsi alla corrispondente voce in italiano. Il glossario verrà aggiornato ed implementato periodicamente con nuovi termini. |
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Absolute risk (vai alla voce Rischio assoluto)
Algoritmo Nel passato, il termine era quasi equivalente a "formula" o a combinazione di formule. Oggi, specialmente nel linguaggio del calcolo automatico, significa una relazione esplicita che permette il calcolo di una quantità. Esistono algoritmi elaborati dalle diverse società scientifiche internazionali sulla base degli studi epidemiologici allo scopo di determinare il rischio cardiovascolare individuale, primo passo nella prevenzione delle malattie cardiovascolari. Il Rischio Cardiovascolare esprime la probabilità di andare incontro ad un evento cardiovascolare maggiore entro un certo intervallo di tempo (in genere 10 anni). L'algoritmo di Framingham è forse quello più noto e fino a qualche anno fa veniva utilizzato anche nel nostro Paese per la stima del rischio cardiovascolare. L'algoritmo, derivato da Anderson K.M. et al. nel 1991 dallo studio Framingham, calcola la probabilità di un evento cardiovascolare in un determinato intervallo di tempo (di solito 5 e 10 anni), su pazienti di ambo i sessi in età compresa fra 35 e 70 anni, basandosi su 7 fattori di rischio indipendenti: età, sesso, pressione arteriosa sistolica, rapporto colesterolo totale/HDL, fumo, diabete, ipertrofia ventricolare sinistra.In realtà il calcolo del rischio secondo i parametri di Framingham lo sovrastima nelle popolazioni mediterranee rispetto a quelle nordamericane. Da ciò la necessità di realizzare una più corretta stima del rischio basandosi su dati epidemiologici italiani: è quanto ha fatto l'ISS in collaborazione con l' Osservatorio Epidemiologico Italiano. La Carta del rischio elaborata si basa su studi epidemiologici condotti su coorti Italiane; tale strumento è stato approvato dal Ministero della Salute e proposto ai medici per valutare oltre che il rischio cardiovascolare individuale, anche la rimborsabilità dei farmaci in nota 13. Per contro le linee guida europee si basano, per il calcolo del rischio, sullo studio SCORE (Systematic Coronary Risk Evaluation) che condensa i dati emersi da 12 studi di coorte in 12 stati europei ed utilizza l'algoritmo SCORE differenziato per le popolazioni dell'Europa del Nord e del Sud (2 diverse carte del rischio). Gli algoritmi di calcolo utilizzati nel calcolatore di rischio coronarico sono derivati da studi effettuati su categorie specifiche di pazienti. Sono quindi applicabili a pazienti che possano rientrare in determinati criteri di selezione. Inoltre, entrambi i sistemi di calcolo possono essere applicati esclusivamente in prevenzione primaria: su pazienti, cioè, che non abbiano ancora avuto un evento cardiovascolare (malattia coronarica clinicamente provata, angioplastica o by-pass aorto-coronarico, TIA, ictus, claudicatio intermittente).
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
| Bias Errore sistematico, o distorsione, presente in uno studio, che si ripercuote sui suoi risultati determinando uno scarto tra risultati ottenuti e quelli che si sarebbero dovuti ottenere in assenza di tale errore. I tre errori sistematici più importanti sono: a) bias di selezione o di campionamento, quando il campione indagato è stato scelto e assemblato in modo errato; b) bias di misurazione, quando i metodi o gli strumenti di misurazione non sono adeguati al campione e all'obiettivo dello studio, o sono imprecisi, o sono diversi tra i pazienti studiati; c) bias da effetti estranei, quando è presente un fattore estraneo di confondimento.
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Campione (Sample)
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Dato riservato (vai alla voce Dato sensibile) Dato sensibile Informazione su variabili che riguardano la sfera strettamente personale del rispondente. Secondo il Codice sulla protezione dei dati personali (d.lgs. 196/2003), art.4, sono considerati dati sensibili, e dunque la loro raccolta e trattamento sono soggetti sia al consenso dell'interessato sia all'autorizzazione preventiva del Garante per la protezione dei dati personali (art. 26), i dati personali, idonei a rivelare:l'origine razziale ed etnica, le convinzioni religiose, filosofiche o di altro genere, le opinioni politiche, l'adesione a partiti, sindacati, associazioni od organizzazioni a carattere religioso, filosofico, politico o sindacale, lo stato di salute e la vita sessuale
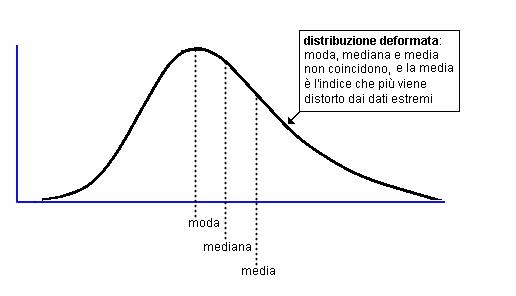
La media ±1DS include il 66% dei valori di una distribuzione normale.
|
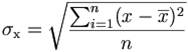
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Effetto Hawthorne
Esito (vai alla voce End point)
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Fattore confondente (Confounder)
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Gaussiana (Gaussian distribution) (vai alla voce Distribuzione normale)
Grafico a barre Grafico a torta  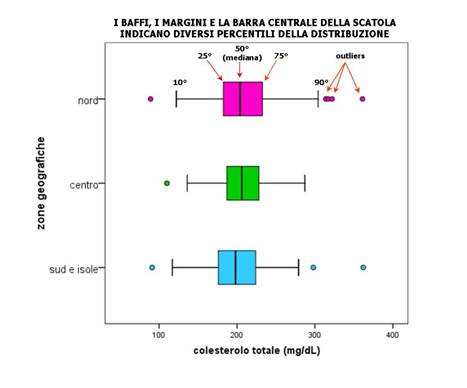
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Hazard ratio (HR)
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Incidence rate (vai alla voce Tasso di incidenza)
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Longitudinal study (vai alla voce Studio longitudinale) |
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Marcatore (Marker)
I "tassi" sono invece misure dinamiche, che rappresentano la variazione di una quantità per la variazione unitaria di un'altra quantità (generalmente il tempo).
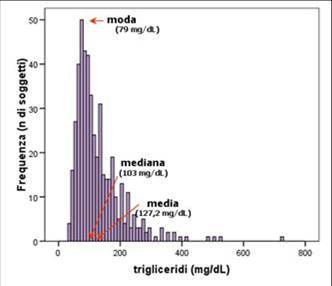
Misure di tendenza centrale (vai alla voce Indici di tendenza centrale)
|
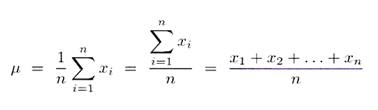
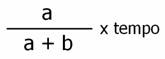
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Normal curve (vai alla voce Curva normale)
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Observational study (vai alla voce Studio di coorte)
Odds=p/(1-p)
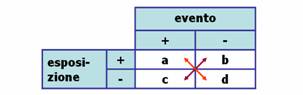
(a/c) / (b/d) = (a/b) x (c/d) Nello studio caso-controllo viene usato calcolato per stimare retrospettivamente il rischio relativo che non è calcolabile (infatti non si possono calcolare le incidenze nei casi e nei controlli). Tale stima è buona soprattutto con malattie rare o popolazioni grandi. Come per il rischio relativo, un valore superiore a 1 indica un aumento di rischio legato all'esposizione, un valore inferiore a 1 ha il significato di un effetto benefico o protettivo. Un valore pari a 1 indica l'indifferenza tra i due esposizioni.
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
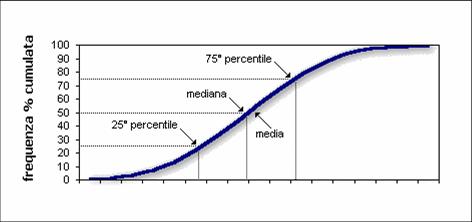
Percentile
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Quoziente
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Randomizzazione (Randomization)
Range = valore max - valore min. Se un range è un numero elevato indica che il gruppo è molto distribuito; al contrario un range basso indica che i dati si concentrano su pochi valori e vicini fra loro.
[a/(a+b)]/[c/( c+d)]
|

| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Sample (vai alla voce Campione)
Non essendo possibile la stima corretta e diretta dell'incidenza, viene usato l'odds ratio.
|


| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
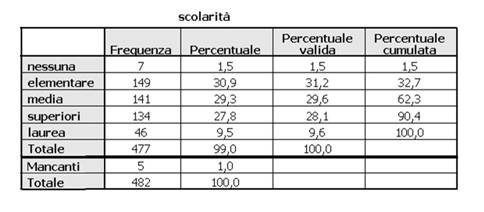
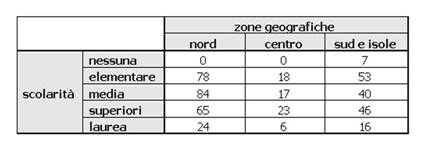
Tabelle
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Unità campionaria
|
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Valore abnorme
|
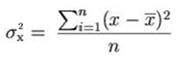
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |
|
Years of potential life lost (YPLL) (vai alla voce Anni potenziali di vita persi) |
| top | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | top |